Q-learningアルゴリズムの詳細は 3.3 マルコフ決定過程(MDP)の環境における強化学習(Q-learning)を参照。
十分に時間が経過して,正しくQ値の推定学習がなされた場合, 最大のQ値を持つ行動が最適な行動となる。 このとき,ε-greedy行動選択戦略においてε=0とすれば, エージェントは最適な行動を実行する。
下図に示すサーバシステムへ,
0から3までの優先度を持つ顧客がアクセス要求を行う.
あなたはアクセス要求を受け入れる(accept)するか,
拒絶する(reject)かのどちらかの行動を選択できる.
サーバに空きがあるときに顧客のアクセス要求を受け入れると,
顧客の優先度に応じて報酬が与えられる.
サーバの空き状況と到着した顧客の優先度に応じて,適切に
アクセスをコントロールする必要がある.
以下にサーバアクセス制御問題をQ-learningで解くアプレットを示す。
Discount rateは割引率,Learning rateは学習率を表す。
行動選択戦略としてε-greedy戦略をとる。これらの値はスクロールバー
によって調節可能である。
[Run]ボタンを押すと学習を開始する。
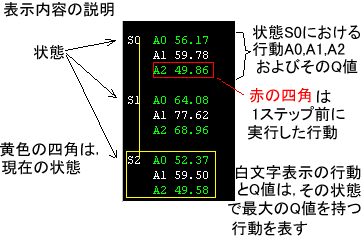
Q-learningエージェントの表示について以下に説明する。
Q-learningアルゴリズムの詳細は 3.3 マルコフ決定過程(MDP)の環境における強化学習(Q-learning)を参照。
十分に時間が経過して,正しくQ値の推定学習がなされた場合,
最大のQ値を持つ行動が最適な行動となる。
このとき,ε-greedy行動選択戦略においてε=0とすれば,
エージェントは最適な行動を実行する。