ICML99 (6/26--30, 1999) 参加報告
16th International Conference on Machine Learning (ICML99)
Bled, Slovenia
平成 11年 7月 7日小林(重)研 木村の研究会資料より(2000.10.17作成)
国際会議全体について
今回のICMLはILP(International conference on Logic Programming)とほぼ合同
で行われた。
ICMLの全ての発表者は25分のプレゼン(発表20分,質疑5分)および
ポスターセッション(2時間)での発表があった。
ICML99 ポスターセッションの様子
論文賞などにノミネートされた優れた論文はプレナリセッションで発表され、
それ以外の論文は2つのセッションで並列に進行された。
今回の参加者のうち主だった強化学習の研究者としては
Sutton, Boyan, Mahadevan などが出席していたが,
Kaelbling, Singh, Littman などは来ていなかった.
野外Pubにて 左からNicolas氏,木村,Dr.Sutton
またCMUのJ.Schneider(Mooreの弟子)やDietterichという研究者が来ていた.
強化学習以外の大御所としてはDecisionTreeのQuinlanや行動科学や認知モデルの
J.R.Andersonが招かれていた.
野外パーティや城内コンサートなど楽しいイベントがあったが,IJCAIやAAAIな
どのような実機によるデモンストレーションなどは全くなかった.
野外パーティの様子1
野外パーティの様子2
会議場の前にある湖とお城
お城の上から湖を臨む
城内での歓迎演奏会の様子
湖上の島に建てられた教会1
今回参加した国際会議において,AIの応用に関する際だった傾向として
WEB上から必要なデータを効率よく収集するためのシステムが目立った.
(Invited Talk 1件,テクニカルセッションでの発表4件)
Suttonのチュートリアル:Reinforcement Learning
強化学習の概要についての説明.
(私はすでに強化学習の基本については理解しているので,
主に一般人へ強化学習を説明するプレゼンテーション方法の参考にするために聴講した)
Suttonの主張のうち,いくつか印象に残ったものを以下に挙げる.
- 生体の適応を例にあげて説明
- Surpervised Learningとの違い…Discovery how to move,
- 強化学習は単なるテクニックボックスではない
- 実機によるデモ(ビデオ):Ball balancing
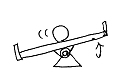
- シーソーの上でボールが左右に転がるので,
左右端に衝突することのないようにシーソーの上下動(リレー)をコントロールする.
- 人間がコントロールすると難しい(タイムスケールが小さいから)
- 強化学習ではActor-Criticを用いてリアルタイムに適応(1~2分)
- シーソーにおもりを付けるなどバランスを変化させても適応
- 「割引率」の割引について,「信頼性」のような説明をしていた
- 計算機シミュレーションによるデモ
- The Mountain Car Problem: x と dx/dt をxy軸とした状態遷移とValue functionの学習の様子

- The Acrobot Problem
- Grid WorldでDynaのデモ:迷路が動的に変化しても対応できる
- 強化学習の応用例について:
- Elevetor control (Crites and Barto)
- TD-Gammon ad Jellyfish (Tesauro, Dahl)
- Inventory Management(生産システム・在庫管理) (Van Roy, Bertsekas, Lee and Tsitsiklis)
- CMU ROBOCUP Soccer Team (Stone and Veloso 1998)
- Many Robots
- Dynamic Channel Assigment (Singh and Bertsekas, Nie and Hayki)
【MEMO】
ビールを飲みながらDr.Suttonと強化学習談義。Dr.Suttonは”Value function is life!”
などと言っていた。そういえば私のボスの小林先生は「世の中これ全て最適化だ!」と
主張されてるし,制御の原先生は「世の中全てフィードバック制御だ」と主張されてた。
その道を極めた学者はみなそれぞれ独特の極論ともいえる思想をもっているなあと感心。
Dietterichのチュートリアル:Hierarchical Reinforcement Learning
階層的強化学習についての解説.ビデオ等によるデモなどは無かったが,
いろいろなアプローチを体系的にまとめており,参考になる.
- 階層化の目的:
- 大規模な問題を小さく分割して解く
- 知識やサブタスクを再利用したり共有する
- 部分観測性に対処する:高レベルの階層が,低レベルにおける部分観測性をカバーする
- シングルエージェントにおける階層化を以下のように分類
- Optionの集合を与え,これらのoptionをどのように選択するかについて学習する.(Precup, Sutton and Singh)
- 部分的な政策の階層構造(a hierarchy of partial policies)を与え,
全体の問題を解くための政策を学習する.(Parr and Russel)
- サブタスクの集合を与え,各サブタスクにおける政策を学習する.
(Mahadevan and Connel), (Sutton, Precup and Singh)
- サブタスクの集合を与え,全体の問題を解くための政策を学習する.(Kaelbling's HDG),
(Singh's Compositional Tasks), (Dayan and Hinton's Fedual Q), (Dieterrich's MAXQ),
(Dean and Lin)
- セミマルコフ決定過程(SMDP)との関連について
- 解の準最適性(suboptimality)について:なるべく最適解に近い解を得るには?
- Mixing Options and Primitives
- Re-Definition of Subtasks (Pseudo Rewards)
- Non-Hierarchical Execution
- 状態の抽象化(State Abstraction)
- Independent State Variables
- Funnel Actions (ある行動を実行すると,特定の状態変数には関係なく状態遷移する)
- 問題をマルチエージェントに分解するのも階層化の一種
- 市場ベースのマルチエージェントシステム
【MEMO】迷路問題の説明において,ロボットが壁にぶつかるとはね返る様子を
「ボインボイン」と言っていた。欧米人の学者が擬態語・擬声語を使うのは珍しいので、
印象に残った。
テクニカルセッション:強化学習研究の動向
テクニカルセッションにおける強化学習関連の発表は 12件ほどあり、
依然として研究者の関心を集める分野であるが、
企業の利益に直結するような応用はまだ少ない.
- POMDP環境下での強化学習:
- [ICML99,pp.307]Learning Policies with External Memory, L.Peshkin, N.Meuleau and L.P.Kaelbling
エージェント内部に,行動によって操作可能なメモリを持たせ,
POMDP環境においてメモリ操作も含めた政策空間を探索/学習させる.
SARSA(λ)とVAPSという政策改善法について比較.
- マルチエージェント:
- [ICML99,pp.371]Distributed Value Functions,
J.Schneider, W.Wong, A.Moore and M.Riedmiller
報酬を分配するのではなく,互いのValueに関する情報をやりとりして
全体の性能を改善していく.理論的面についてまだ不完全.(坪井君がすでにゼミで読んだ)
- [ICML99,pp.325]Implicit Imitation in Multiagent Reinforcement Learning,
B.Price and C.Boutilier
Control AgentとObservation Agentを使って学習.他のエージェントの経験を利用するらしい
- [ICML99,pp.464]Hierarchical Optimization of Policy-Coupled Semi-Markov Decision Processes,
G.Wang and S.Mahadevan
(応用の項目で説明)
- 理論等:
- [ICML99,pp.3]Associative Reinforcement Learning using Linear Probabilistic Concepts,
N.Abe and P.M.Long:
時間的な遅れのない線形の推定問題を扱うアルゴリズムの提案と解析.
- [ICML99,pp.49]Least-Squares Temporal Difference Learning, J.A.Boyan
TD(λ)を行列演算の一種と考え,演算方法としてもっとデータ使用効率の良い
Least-squares TD(λ)を提案.TD(λ)では状態Sと同じ個数の変数に推定値を蓄積していた部分を,
Least-squares TD(λ)ではS×S個の変数にデータを蓄積し,
Valueを求める場合はこのマトリクスの逆行列を明示的に計算する.
- [ICML99,pp.278]Policy invariance under reward transformations:
Theory and application to reward shaping, A.Y.Ng, D.Harada and S.Russell
MDPの報酬関数にある性質を持つポテンシャル関数を足すことにより,
別の等価なMDPに変換してもっと高速に最適政策を求める…らしいが,よく分からない.
- [ICML99,pp.425]Approximation Via Value Unification, P.E.Utgoff and D.J.Stracuzzi
1または0のバイナリ列を入力とし,スカラーの連続値を出力とするような関数近似の方法を提案.
全状態を明示的に保持することなく,木構造を用いる.
プレゼンでは,チェスやオセロの問題を例として挙げていた.
- 応用:
- [ICML99,pp.12]Learning to Optimally Schedule Internet Banner Advertisements, N.Abe and A.Nakamura
平均クリックスルーレートを最大化するようにインターネットバナーをスケジュールする.
- [ICML99,pp.57]Learning to Ride a Bycycle using Iterated Phantom Induction, M.Brodie and G.DeJong
著者らが提案したIterated Phantom Induction を用いて自転車制御の強化学習を改善.
- [ICML99,pp.191]Distributed Robotic Learning: Adaptive Behavior Acquisition for Distributed
Autonomous Swimming Robot in Real-World, D.Iijima, W.Yu, H.Yokoi and Y.Kakazu
蛇ロボットを体節モジュール毎に分散コントロール学習させて,光源方向に泳ぐような行動を獲得.
- [ICML99,pp.335]Using Reinforcement Learning to Spider the Web Efficiently, J.Rennie and A.K.McCallum
Webにおいて特定の種類のページを探すようなタスクに強化学習を適用.各ページを状態,リンクを状態遷移,
目的のページに到達したら報酬を与えるとか言っていた.
- [ICML99,pp.464]Hierarchical Optimization of Policy-Coupled Semi-Markov Decision Processes,
G.Wang and S.Mahadevan
製造ライン(物流ライン:Transfer line)の最適化にセミマルコフ決定過程の強化学習+マルチエージェント,
階層化を適用.トヨタのカンバン方式と比較.
- その他(強化学習とは直接関係ないかも):
- [ICML99,pp.503]A Hybrid Lazy-Eager Approach to Reducing the Computation and Memory Requirements of
Local Parametric Learning Algorithms, Y.Zhou and C.Brodley
計算機のオンデマンドサービスにおけるリソースの予測を行う.
Lazy-learning: データ(事例)を蓄積しておき,
queryが来るまで何もしない.メモリを食うが計算コストはかからない.
Eager-learning: モデルを学習する.メモリは食わないが,計算コストがかかる.
今回は強化学習の枠組をマルチエージェントへ拡張する研究が進んだように見え
る.単に報酬を分配したり個々が勝手に動くのではなく,Valueの情報を伝搬し
たり,仮想的な報酬をやりとりするが全体としての報酬量はつじつまが合うよう
になっていたりする.しかし解析的にはまだ弱い.
Web関連への適用例が目立って増加したが,方法論的にはバラバラである.
一時的な流行ではないかと批判的な意見もあるが,単に特定のトピックスのペー
ジを検索する以外の,別のweb応用へ適用するような研究は増えるかもしれない.
例えばインターネットバナーの宣伝効果を自動的に高めるような強化学習など。
TD(λ)のような適正度の履歴(eligibility trace)を用いる学習方法は,
平均報酬においても成り立つかどうかについてSuttonに意見を求めたところ,
「実はまだ査読中なので話しちゃダメなんだけど…」と言いつつ,Tsitsiklisら
がそのようなアルゴリズムを完成させたことを教えてくれた.
よって,平均報酬のValue関数を用いたActor-Criticも可能なはずだとのコメン
トを得た.
ICML99 ポスターセッションで気になった発表のポスター1
ICML99 ポスターセッションで気になった発表のポスター2
ICML99 ポスターセッションで気になった発表のポスター3
ICML99 ポスターセッションで気になった発表のポスター4
ICML99 ポスターセッションで気になった発表のポスター5
ICML99 ポスターセッションで気になった発表のポスター6
ICML99 ポスターセッションで気になった発表のポスター7
MEMO 【最低限知っていなければならない強化学習の常識】
1) 環境モデル:MDP, セミマルコフ決定過程(SMDP), POMDP
2) 学習アルゴリズム:TD(λ), Q-learning, Sarsa(λ), 政策反復法(Policy iteration)
3) 最適性評価:割引報酬/平均報酬,Value functions, DP
4) 行動選択方法:ε-greedy, ボルツマン選択
5) 関数近似:Linear architectures (table, CMAC), Non-linear (Neural-Network)
6) その他: 適正度の履歴(eligibility trace),モデルベース手法,プラニング, exploration vs exploitation trade-off
映像記録
ICML99 ポスターセッションの様子
野外Pubにて 左からNicolas氏,木村,Dr.Sutton
野外パーティの様子1
野外パーティの様子2
会議場の前にある湖とお城
お城の上から湖を臨む
城内での歓迎演奏会の様子
湖上の島に建てられた教会1
湖上の島に建てられた教会2
湖上の島に建てられた教会3
湖から流れ出す川にかけられた石橋
城壁の下からお城を見上げる
お城の上から城壁の下を見る
お城の正面入口
城内の中庭へ続くスロープ
城内の中庭
湖の東側に続く住宅
宿泊したホテルのビアガーデンのメニュー
野外PUBにて:Dr.Sutton と Nicolas氏
湖に面する道路のトンネル
湖のほとりの水面
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}