嫮壔妛廗偵傛傞俉帺桼搙係懌儘儃僢僩偺堏摦惂屼婯懃妉摼丗
摨堦偺妛廗婍偱堎側傞儘儃僢僩偺惂屼婯懃傪摼傞

 夋柺僋儕僢僋偱奼戝昞帵
夋柺僋儕僢僋偱奼戝昞帵
忋偺俀偮偺夋憸偵帵偡係懌儘儃僢僩偺奺媟偼丆
俀屄偺埵抲惂屼僒乕儃儌乕僞偱嬱摦偝傟丆慡懱偱俉帺桼搙偱偁傞丏
僋儌宆儘儃僢僩偺OCT1偺奺媟偺俀偮偺儌乕僞偼偦傟偧傟儕僼僩媟丆僗僀儞僌媟傪庴偗帩偮丏
儕僼僩媟偼忋壓曽岦丆僗僀儞僌媟偼慜屻曽岦傊懌愭傪塣傇栶妱傪帩偮丏
偦傟偵懳偟偰僀僰宆儘儃僢僩OCT2偺奺媟偺俀偮偺儌乕僞偼摨條偵戞堦娭愡丆戞擇娭愡傪庴偗帩偮偑丆
奺媟偺俀偮偺儌乕僞偑嬱摦偡傞娭愡幉偼暯峴偱偁傝丆
懌愭傪塣傇曽岦偵偮偄偰栶妱暘扴偑側偔丆屳偄偺摦嶌偑姳徛偡傞偨傔丆
惂屼婯懃偺峔抸偼OCT1傛傝傕崲擄偱偁傞丏
奺娭愡偲儌乕僞斣崋偺懳墳偼丆OCT1偵偮偄偰偼
OCT1Motors.gif ,
OCT2偵偮偄偰偼 Oct2MotorsM.gif ,偵偦傟偧傟帵偡丅
OCT1偱偼斀帪寁夞傝偵懳墳晅偗傜傟偰偄傞偺偵懳偟丆
OCT2偱偼嵍懁慜屻丆塃懁慜屻偺弴斣偱妱傝摉偰傜傟偰偄傞揰偱傕峔憿揑偵堎側傞丏
妛廗栚昗
妛廗栚昗偼丆側傞傋偔懍偔傑偭偡偖偵慜恑偡傞惂屼婯懃傪妉摼偡傞偙偲偱偁傞丏
偙偺儘儃僢僩傪惂屼偡傞僐儞僩儘乕儔偑妛廗庡懱偺乽僄乕僕僃儞僩乿偵側傝丆
儘儃僢僩杮懱傪娷傔偨奜奅偑僄乕僕僃儞僩偵偲偭偰偺乽娐嫬乿偵側傞丏
僄乕僕僃儞僩偼帠慜偵娐嫬傗儘儃僢僩偺僟僀僫儈僋僗傪抦傜偝傟偰偄側
偄偨傔丆帋峴嶖岆傪捠偠偰惂屼婯懃傪宍惉偟偰偄偔偙偲偑媮傔傜傟傞丏
僄乕僕僃儞僩偺曐帩偡傞惂屼婯懃偼丆忬懺擖椡偐傜峴摦傊偺妋棪暘晍
偲偄偆宍幃偺惌嶔娭悢偱昞尰偝傟傞丏
僄乕僕僃儞僩偼帋峴嶖岆傪捠偠偰惌嶔娭悢偺僷儔儊乕僞傪夵慞偡傞丏
栤戣愝掕
奺帪娫僗僥僢僾偵偍偄偰僄乕僕僃儞僩偼俉屄偺僒乕儃儌乕僞偺妏搙傪娤應偟偰
尰嵼偺忬懺偲偟丆惌嶔娭悢偵廬偭偰峴摦傪慖戰偡傞丏
峴摦偼俉屄偺儌乕僞妏搙偺栚昗抣偱偁傞丏
傛偭偰尰嵼偺忬懺娤應偼侾僗僥僢僾慜偵弌椡偟偨峴摦偵摍偟偄丏
OCT1偱偼媟摨巑偺姳徛傪柍偔偡偨傔丆幚嵺偺儌乕僞傊偺巜椷抣偼
儌乕僞2,8偺傒 -64乣127 偺斖埻丆偦傟埲奜偺儌乕僞偱偼 -128乣63偺斖埻偵惂尷偟偰偁傞丏
OCT2偼慡儌乕僞偑 0乣 255偺斖埻偱摦嶌偡傞丏
僐儞僩儘乕儔偱偼忬懺擖椡傗峴摦弌椡傪椉儘儃僢僩嬫暿側偔埖偆偨傔丆
偙傟傜偺斖埻傪慡偰 [0,1] 偱惓婯壔偡傞丏
OCT1LMH.jpg , OCT2LMH.jpg
偼奺儘儃僢僩偺慡儌乕僞傊偦傟偧傟嵍偐傜嵟彫丆拞怱丆嵟戝抣偺妏搙巜椷僐儅儞僪傪
梌偊偨偲偒偺儘儃僢僩偺巔惃偱偁傞丏
僐儞僩儘乕儔偑峴摦傪慖戰屻丆
OCT1偺応崌栺 0.5昩屻丆OCT2偺応崌栺 0.25昩屻偵忬懺慗堏寢壥偲偟偰曬廣偑梌偊傜傟丆
師偺帪娫僗僥僢僾傊偲恑傓丏
儘儃僢僩屻曽偵帵偝傟傞俀屄偺幵椫偼丆儃僨傿偺堏摦傪専弌偟偰
曬廣怣崋傪惗惉偡傞丏俀偮偺幵椫偺堏摦懍搙暯嬒偼儘儃僢僩偺慜恑懍搙傪帵偟丆
俀偮偺幵椫偺堏摦懍搙偺嵎暘偼儘儃僢僩偑慁夞偟偰偄傞偙偲傪帵偡丏
儘儃僢僩偺妛廗栚昗偼傑偭偡偖偵慜恑偡傞偙偲側偺偱丆奺帪娫僗僥僢僾偱偺
曬廣偼丆俀偮偺幵椫偺堏摦懍搙暯嬒偐傜嵎暘偺愨懳抣傪堷偄偨抣偲偟偨丏
幵椫偼捈宎 5cm偱200僷儖僗乛夞揮偺怣崋傪惗惉偡傞丏
俀偮偺儘儃僢僩偼忋婰偺偲偍傝媟偺峔憿忋OCT2偺曽偑妛廗崲擄偱偁傞丏
OCT1偲OCT2偱偼媟偲儌乕僞偺弴斣傗攝抲傕堎側傞丏
傑偨丆侾僗僥僢僾偁偨傝偺帪娫偑OCT2偱偼OCT1偺敿暘偱偁傝丆
侾僗僥僢僾慜偺峴摦弌椡傪尰嵼偺忬懺娤應偲偡傞偨傔丆
儌乕僞偑捛廬偱偒側偄応崌偵偼忬懺娤應偑晄姰慡偵側傝丆
妛廗傗惂屼偑OCT1傛傝偝傜偵崲擄偵側傞梫慺偑偁傞丏
杮尋媶偱偼丆
崲擄偲巚傢傟傞OCT2偺摦嶌妉摼傪OCT1偲慡偔摨堦偺妛廗婍偱峴偆丅
幚尡僾儘僌儔儉
嫮壔妛廗僱僢僩儚乕僋僾儘僩僐儖
彫椦尋媶幒偱巊梡偟偰偄傞幚尡梡偺僜僼僩偲僾儘僩僐儖
妛廗偵傛傞堏摦懍搙偺岦忋偺條巕
OCT1
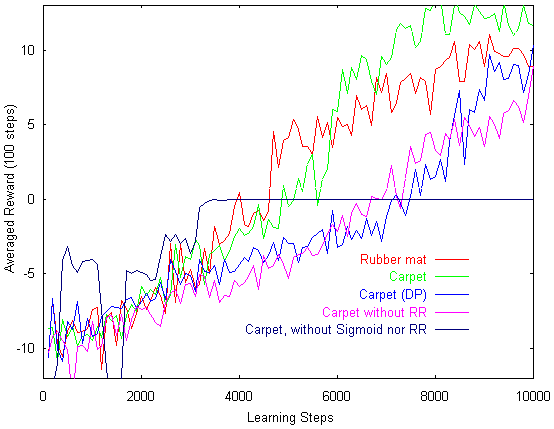
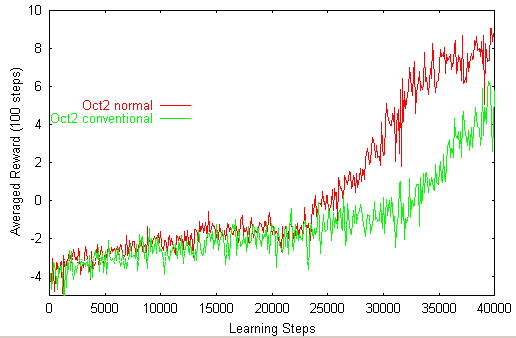
OCT2
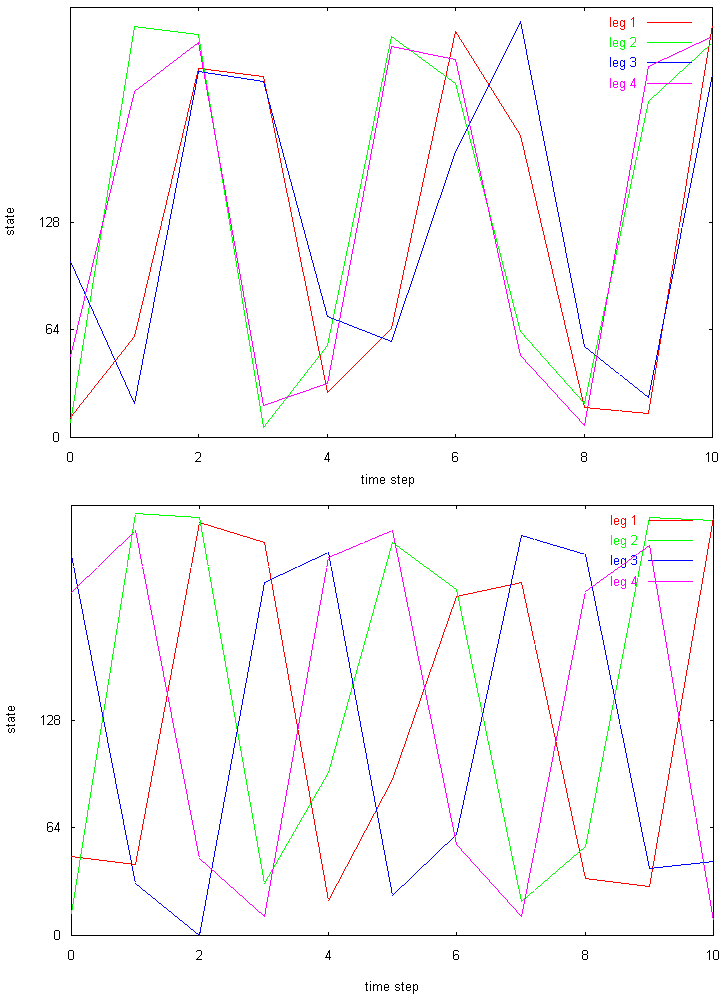
妛廗偵傛偭偰妉摼偟偨曕梕(gait pattern)
OCT2
寁應偲惂屼Vol.40, No.10 (2001) 偺昞巻傪忺偭偨儘儃僢僩偺幨恀
 僋儕僢僋偱奼戝昞帵
僋儕僢僋偱奼戝昞帵
儉乕價乕僼傽僀儖
- OCT1儘儃僢僩乮僋儌宆乯妛廗弶婜儔儞僟儉摦嶌
./movie/OCT1RubberRandom.mpg 栺20昩, 4.29MB
- OCT1儘儃僢僩乮僋儌宆乯僑儉儅僢僩忋偱10,000 step 妛廗屻
./movie/OCT1Rubber10k_1.mpg 栺17昩, 4.75MB 儘儃僢僩懁柺
./movie/OCT1Rubber10k_2.mpg 栺28昩, 7.54MB 儘儃僢僩惓柺
- OCT1儘儃僢僩乮僋儌宆乯僇乕儁僢僩忋偱20,000 step 妛廗屻
./movie/OCT1Carpet20kN_1.mpg 栺31昩, 6.67MB 儘儃僢僩懁柺
./movie/OCT1Carpet20kN_2.mpg 栺39昩, 8.18MB 儘儃僢僩惓柺
- OCT2儘儃僢僩乮僀僰宆乯僇乕儁僢僩忋偱妛廗弶婜儔儞僟儉摦嶌
./movie/Oct2Yama0j_0s.mpg 栺26昩, 1.67MB
- OCT2儘儃僢僩乮僀僰宆乯僇乕儁僢僩忋偱40,000 step 妛廗屻
./movie/OCT2Carpet40K.MOV 栺10昩, 5.26MB 乮僋僀僢僋僞僀儉儉乕價乕乯
妉摼偟偨摦嶌傪娤嶡偡傞偲丆暊晹傪偙偡傞傛偆側曕偒曽傪妉摼偟偰偄傞丅偙傟偼暊晹偑彴偵晅偄偰傕
慜恑摦嶌偵偼巟忈偑側偐偭偨偨傔偱偁傞偲峫偊傜傟傞丅傕偟暊晹偑彴偵晅偐側偄摦嶌偺妉摼傪
偝偣傞丄暊晹偵僙儞僒乕傪愝偗丄暊晹偑彴偵晅偄偨傜敱乮晧偺曬廣乯傪梌偊傞傛偆偵偡傟偽椙偄丅
偙偺傛偆偵捈姶揑偵暘偐傝堈偔娙扨側曬廣傪愝掕偡傞偩偗偱丄偦傟傛傝傕偼傞偐偵暋嶨偝偑戝偒側
惂屼婯懃傪帺摦揑偵妉摼偱偒傞揰偑嫮壔妛廗偺戝偒側摿挜偱偁傞丅
娭楢榑暥
- 栘懞 尦丆嶳壓 摟丆彫椦 廳怣丆
嫮壔妛廗偵傛傞係懌儘儃僢僩偺曕峴摦嶌妉摼丆
揹婥妛夛 揹巕忣曬僔僗僥儉晹栧帍, Vol.122-C, No.3, pp.330--337 (2002).
postscript file, iee0107modified.ps (10.3MB)
PDF file, iee0107modified.pdf (268KB)
- Kimura, H., Yamashita, T. and Kobayashi, S.:
Reinforcement Learning of Walking Behavior for a Four-Legged Robot,
40th IEEE Conference on Decision and Control (CDC2001), pp.411--416 (2001).
6 pages, postscript file, INV2103.ps (6MB)
PDF file, INV2103.pdf (205KB)
敪昞梡OHP PAGE01,
PAGE02,
PAGE03,
PAGE04,
PAGE05,
PAGE06,
PAGE07,
PAGE08,
PAGE09,
PAGE10,
PAGE11,
PAGE12,
PAGE13,
PAGE14,
PAGE15,
PAGE16,
PAGE17.
乮曗懌乯敪昞帒椏拞偺僌儔僼偲web偱帵偟偨僌儔僼偑堦晹怘偄堘偭偰偄傑偡偑丄web忋偺僨乕僞偼屻偱庢傝捈偟偨傕偺偱偡丅
- 嶳壓摟丆栘懞 尦丆彫椦 廳怣丆
嫮壔妛廗偵傛傞懡懌曕峴儘儃僢僩偺幚尰丆
寁應帺摦惂屼妛夛 戞13夞帺棩暘嶶僔僗僥儉僔儞億僕僂儉, pp.111--116 (2001)
帺慠岡攝Actor-Critic傪巊梡偟偨儘儃僢僩
忋婰偺儘儃僢僩偺嫮壔妛廗傾儖僑儕僘儉(Actor-Critic)傛傝恑曕偟偨帺慠岡攝Actor-Critic傪巊偭偨儘儃僢僩
懌偺儌乕僞偼俉屄偱偡偑忬懺擖椡偑懌偺妏搙乮俉師尦乯偺傎偐丄
係偮偺懌愭僙儞僒傕娷傫偱偄傑偡丅
埲壓偺儉乕價乕偼 15000 step妛廗屻偺摦嶌偺條巕丅幚帪娫偱偼俀侽乣俁侽暘
 NGAC15000step.mpg 栺13昩, 2.3MB
NGAC15000step.mpg 栺13昩, 2.3MB
偦偺懠儉乕價乕1 (3.68MB) 妛廗弶婜
偦偺懠儉乕價乕2 (4.75MB) 妛廗搑拞1
偦偺懠儉乕價乕3 (2.69MB) 妛廗搑拞2
偦偺懠儉乕價乕4 (3.07MB)
偦偺懠儉乕價乕6 (1.62MB)
偦偺懠儉乕價乕7 (3.07MB)
偦偺懠儉乕價乕8 (2.69MB)
偦偺懠儉乕價乕9 (2.00MB)
偦偺懠儉乕價乕10 (2.38MB)
娭楢榑暥
- 栘懞 尦丗
揔惓搙偺棜楌傪梡偄偨帺慠岡攝Actor-Critic朄
寁應帺摦惂屼妛夛 戞19夞帺棩暘嶶僔僗僥儉僔儞億僕僂儉乮2007擭1寧乯pp.67--72.
6 pages, PDF file, sice20070129.pdf (247KB)
Hajime Kimura:
Natural Gradient Actor-Critic using Eligibility Traces,
Conference Proceedings of the 19th SICE Symposium on Decentralized Autonomous Systems, pp.67--72 (2007).
NGAC_demo.zip 帺慠岡攝Actor-Critic傾儖僑儕僘儉偺僨儌僾儘僌儔儉
- Hajime Kimura:
Natural Gradient Actor-Critic Algorithms using
Random Rectangular Coarse Coding,
The Society of Instrument and Control Engineers (SICE) Annual Conference 2008, 2A17-1, pp.2027--2034 (August 20--22, 2008).
8 pages, PDF file, SICE20080821.pdf (450KB)

 夋柺僋儕僢僋偱奼戝昞帵
夋柺僋儕僢僋偱奼戝昞帵 僋儕僢僋偱奼戝昞帵
僋儕僢僋偱奼戝昞帵{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}