
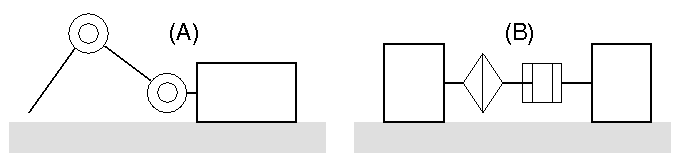
Although the mechanics between the robot A and B are absolutely different, the input-output (state-action) for the controllers are the same.
In this demonstration, we use the same RL algorithm for both robots in order to explain "RL will save our programming cost".
Although the RL algorithms are the same, obtained control rules are different and each robot learns appropreately.
We adopt an actor-critic algorithm since the state and action are continuous.
The state input is of two dimensional that represents joints' angles (theta 1 and theta 2),
and the action output is also two dimensional that is a destination angles of the servo motors.
But, these robots are so cheap, we use the executed action in the previous step
as a substitute for the current state input.
Therefore, a hidden-state problem occurs when the servo motors fail moving the joints to the destination in time.
The decision interval is about 0.2 sec.
Examples of the obtained behavior. (ROBOTSM.jpg 640x792, 119KBytes)
The behavior of the ROBOT-A.
Small size: ROBOT_As.mpg (176x112 MPEG1 movie, 4.82MB)
Large size: ROBOT_A.mpg (352x240 MPEG1 movie, 22.2MB)
ROBOT-B.
The parameters are the same as the ROBOT_A.
Small size: ROBOT_Bs.mpg (176x112 MPEG1 movie, 2.2MB)
Large size: ROBOT_B.mpg (352x240 MPEG1 movie, 9.92MB)
Animation gif(65.7KB)
Hajime Kimura, Shigenobu Kobayashi:
Reinforcement Learning using Stochastic Gradient Algorithm and its Application
to Robots,
The Transaction of the Institute of Electrical Enginners of Japan, Vol.119, No.8 (1999)
(in Japanese, sorry)
Although this paper is written in Japanese, you may easily follow the mathematics.
4 pages, postscript file, denki99.ps (Japanese fonts are included in the file.)
PDF file, denki99.pdf
 .
. {kind=link}
{kind=link}