This page is written in Japanese.
嫮壔妛廗偺揔梡椺丗儘儃僢僩偺曕峴摦嶌妉摼
偙偙偱帵偡椺偼丆嫮壔妛廗偑帩偮埲壓偺俀偮偺摿挜偵偮偄偰帵偡偙偲傪堄恾偟偰偄傞丅
- 嫮壔妛廗偵傛傞惂屼僾儘僌儔儈儞僌偺帺摦壔丒徣椡壔
- 僴儞僪僐乕僨傿儞僌傛傝傕桪傟偨夝偺妉摼丆
摿偵晄妋幚惈乮杸嶤傗僈僞丆怳摦丆岆嵎側偳乯傗
寁應偑崲擄側枹抦僷儔儊乕僞偑懡偄応崌丆恖娫偺忢幆偱偼懳張偟愗傟側偄偙偲偑
梊憐偝傟丆嫮壔妛廗偺岠壥偑婜懸偱偒傞丏
俀帺桼搙儘儃僢僩

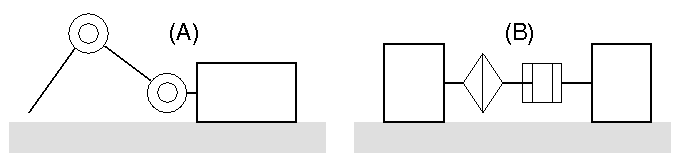
Fig.A,B: 妛廗懳徾偲偟偨儘儃僢僩婡峔偺偦偺柾幃恾丏
A偼儃僨傿偐傜俀愡儕儞僋傾乕儉偑挘傝弌偡峔憿傪帩偪丆B偼儃僨傿偵偹偠傝偲嬋
偘傪峴偆峔憿傪帩偮丏
A偲B偼儊僇僯僘儉揑偵慡偔堎側傞偑丆姰慡偵摨偠妛廗傾儖僑儕僘儉
傪揔梡壜擻丏
Fig.A, B 偵帵偡傛偆偵丆儌乕僞傪俀屄搵嵹偟偨俀帺桼搙偺婡峔傪帩偮儘儃僢
僩A偍傛傃B偵懳偟丆姰慡偵摨堦偺嫮壔妛廗傾儖僑儕僘儉傪揔梡偟丆岠棪傛偔慜恑
偡傞摦嶌傪妉摼偡傞丏
徻偟偔偼岞昞榑暥堦棗偺埲壓偺夝愢婰帠傪嶲徠丗
- 栘懞 尦丆彫椦 廳怣:
妋棪揑孹幬朄傪梡偄偨嫮壔妛廗偲儘儃僢僩傊偺揔梡丆
揹婥妛夛, 揹巕丒忣曬丒僔僗僥儉晹栧帍, Vol.119, No.8, pp.931--934 (暯惉11擭).
4 pages, postscript file, denki99.ps (1,568KBytes)
4 pages, PDF file, denki99.pdf (135KBytes)
- 栘懞 尦丆媨嶈 榓岝丆彫椦 廳怣丗
嫮壔妛廗僔僗僥儉偺愝寁巜恓丆
寁應偲惂屼, 寁應帺摦惂屼妛夛 Vol.38, No.10, pp.618--623 (1999).
6 pages, postscript file, sice99.ps (1.31MB)
PDF file, sice99.pdf (148KB)
僄乕僕僃儞僩偡側傢偪儘儃僢僩偺僐儞僩儘乕儔偑妉摼偡傋偒惂屼婯懃偼丆
尰嵼偺娭愡偺妏搙傪忬懺擖椡偲偟偰梌偊傜傟偨偲偒丆
慜恑偡傞傛偆側摦偒偲側傞傛偆偵儌乕僞偺栚昗抣偲偡傋偒娭愡偺妏搙傪
弌椡偡傞偙偲偱偁傞丏
儘儃僢僩偺妛廗栚昗偼丆岠棪傛偔慜恑偡傞偙偲側偺偱丆
奺帪崗偵偍偗傞儃僨傿偺慜恑懍搙傪僄乕僕僃儞僩偑曬廣偲偟偰庴偗庢傞傛偆愝掕
偡傞丏
僄乕僕僃儞僩偲儘儃僢僩偼埲壓偺傗傝偲傝傪峴偆丏
- 僄乕僕僃儞僩偼忬懺娤應偲偟偰儘儃僢僩偺娭愡偺妏搙兤1, 兤2傪
庴偗庢傞丏
- 僄乕僕僃儞僩偼峴摦弌椡偲偟偰娭愡儌乕僞偺妏搙偺栚昗抣a1, a2傪弌椡丏
- 儘儃僢僩偼栚昗妏搙偺曽岦傊奺儌乕僞傪摦偐偡丏
- 栺0.2昩屻丆儘儃僢僩偼儃僨傿偑堏摦偟偨嫍棧傪寁應偟丆偦偺抣傪曬廣偲
偟偰僄乕僕僃儞僩偵梌偊傞丏
- 僗僥僢僾1偵栠偭偰孞傝曉偡丏
忋婰偺傛偆偵愝掕偡傞偙偲偵傛傝丆儘儃僢僩傪岠棪傛偔慜恑偝偣傞妛廗栤戣偼丆
僄乕僕僃儞僩偑棙摼乮曬廣偺憤寁乯傪嵟戝壔偡傞傛偆惌嶔傪扵嶕偡傞嵟揔壔
栤戣傊婣拝偝傟傞丏
偙偙偱拲栚偡傋偒揰偼丆儘儃僢僩A偲B偑儊僇僯僘儉揑偵慡偔堎側傞偵傕偐偐傢
傜偢丆嫮壔妛廗栤戣偲偟偰尒傞偲摨偠偵側傞揰偲丆
媮傔傞傋偒惂屼婯懃偑斾妑揑暋嶨偱偁傞妱偵丆
曬廣偺愝掕偑嬌傔偰娙扨側揰偱偁傞丏
傛偭偰丆
儘儃僢僩A傊揔梡壜擻側嫮壔妛廗傾儖僑儕僘儉偑丆壗傕曄峏偡傞偙偲側
偔儘儃僢僩B偵傕揔梡偱偒傞偲偄偆堄枴偲丆
愝寁幰偑嬌傔偰娙扨側曬廣愝掕傪偡傞偩偗偱暋嶨側惂屼婯懃傪帺摦揑偵摼傜傟傞
偲偄偆俀偮偺堄枴偵偍偄偰丆
嫮壔妛廗偵傛傞惂屼婯懃僾儘僌儔儈儞僌偺帺摦壔丒徣椡壔傪幚尰
偟偰偄傞丏
忬懺娤應偱偁傞娭愡偺妏搙兤1, 兤2偍傛傃峴摦弌椡偱偁傞娭愡儌乕
僞偺妏搙偺栚昗抣 a1, a2 偼丆偦傟偧傟 0 偐傜 255傑偱偺惍悢抣傪偲傞丏
曬廣偺抣偼 -128 乣 127偺斖埻偺惍悢抣傪偲傝丆儃僨傿偑堏摦偟側偄応崌偼 0
偱偁傞丏
堏摦嫍棧傪寁應偡傞偨傔偵侾夞揮200僷儖僗偺儘乕僞儕乕僄儞僐乕僟偵捈宎3cm
偺幵椫傪晅偗丆僷儖僗偺屄悢傪曬廣偺愨懳抣丆夞揮曽岦傪曬廣偺晞崋偲偟偰寁應
偡傞丏
幚帪娫偱偍傛偦5乣6暘屻偺妛廗拞偺摦嶌椺傪
(ROBOTSM.jpg 640x792, 119KBytes)偵帵偡丏
儘儃僢僩B偵偮偄偰娤嶡偝傟偨偺偼忋偵帵偟偨摦嶌偵椶
帡偡傞摦嶌偺傒偩偭偨(傾僯儊乕僔儑儞gif, 65.7KB)丏
偲偙傠偑儘儃僢僩A偼忋偵帵偟偨摦嶌埲奜偵傕
妛廗搑拞偵偍偄偰偝傑偞傑側僷僞乕儞偑尒傜傟丆忢偵曄壔偑娤應偝傟偨丏
摿偵丆傾乕儉愭抂傪抧柺偵怗傟偨傑傑丆傾乕儉傪寖偟偔忋壓偵摦偐偡偲摨帪偵
傾乕儉帺恎傕嬋偘偨傝怢偽偟偨傝偟偰丆広庢拵偺傛偆偵堏摦偡傞條巕偑娤應偝傟
偨丏偙傟偼傾乕儉傪壓偵摦偐偡偲偒偼傾乕儉愭抂偲抧柺偲偺杸嶤椡偑憹偡偨傔丆
偙偺偲偒傾乕儉傪嬋偘傞偲慜恑偟傗偡偔丆媡偵傾乕儉傪忋偵摦偐偡偲偒偼杸嶤椡
偑尭傞偨傔丆偙偺偲偒傾乕儉傪怢偽偡偲傎偲傫偳屻戅偡傞偙偲偑側偄偙偲傪棙梡
偡傞傕偺偱偁傞丏偙偺傛偆側摦嶌偼幚嵺偵帋峴嶖岆偟側偄尷傝丆
妉摼偡傞偺偼崲擄偱偁傞丏
曇廤嵪傒MPEG 儉乕價乕僼傽僀儖 乮MPEG1僐乕僪乯
媄弍僨乕僞
儚儞僠僢僾儅僀僐儞PIC傪梡偄偨儌乕僞僪儔僀僽夞楬
幙栤傗僐儊儞僩摍偼儊乕儖偵偰偳偆偧丗
{kind=link}
{kind=link}