迷路問題 (A Maze Problem):
状態遷移に不確実性がない場合
以下のように,ラベル付けされた現在位置を状態として観測可能な迷路がある。
各意思決定において4種類の行動のうちどれか1つを実行すると,
その行動に応じた状態遷移を行う。
ゴールに到達すると正の報酬が与えられ,ゴール状態で行動を実行すると
無条件でS0へジャンプする。(下図とその下のアプレットを参照)
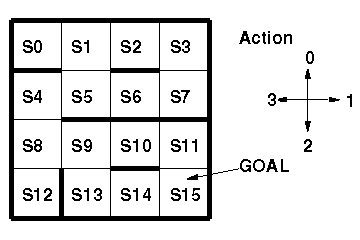
よって,獲得報酬を最大化するような制御規則(状態→行動への写像)は,
ゴールへ最短パスで到達する制御規則となる。
問題:迷路の全体図を見ないで試行錯誤を行い,ゴールまで最短ステップで到達する制御規則を求めよ。
Let's try!
強化学習アルゴリズムのベンチマークとしてこれに類似する迷路問題は頻繁に取り上げられている。
よく見かける迷路問題のデモの多くは迷路全体が(人間に対して)表示されているため,
きわめて簡単な問題を扱っているように感じてしまうが(実際簡単なのだが),
強化学習エージェントが観測できる情報は,本アプレットのようにごく限られたものである。
強化学習エージェントと同じ視点で迷路を見てみると,
人間にとってやや難しい問題に見えるだろう。
この迷路に状態遷移の不確実性などが付加されると,きわめて困難な問題になる。
本例題を代表的な強化学習アルゴリズム「Q-learning」を使って解いてみる
もどる