Q-learningアルゴリズムの詳細は 3.3 マルコフ決定過程(MDP)の環境における強化学習(Q-learning)を参照。
A, B, C の3つの町を運転して回るタクシーの問題をQ-learningで学習してみる.
それぞれの町において,以下の (Act0), (Act1), (Act2) の3つの行動のうち
一つを選択して実行できる.
(Act0) 町中を流して客を拾う.
(Act1) タクシースタンドへ行って客を拾う.
(Act2) 無線連絡による呼出しで客を拾う.
行動を実行して客を拾うと,状態が遷移して報酬が得られる.
以下にタクシー問題をQ-learningで解くアプレットを示す。
Discount rateは割引率,Learning rateは学習率を表す。
行動選択戦略としてε-greedy戦略をとる。これらの値はスクロールバー
によって調節可能である。
[Run]ボタンを押すと学習を開始する。
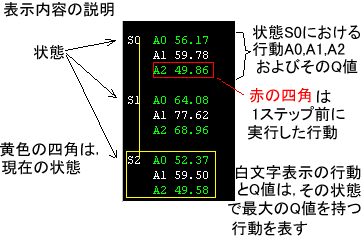
Q-learningエージェントの表示について以下に説明する。
Q-learningアルゴリズムの詳細は 3.3 マルコフ決定過程(MDP)の環境における強化学習(Q-learning)を参照。
十分に時間が経過して,正しくQ値の推定学習がなされた場合, 最大のQ値を持つ行動が最適な行動となる。 このとき,ε-greedy行動選択戦略においてε=0とすれば, エージェントは最適な行動を実行する。
以下に環境の状態遷移確率と報酬設定の詳細を示す。エージェントは学習前においてこれらについては未知なので, 環境を実際に遷移することでこれらの情報を獲得する。| 状態 S(都市) | 行動 a | 遷移確率 | 直接報酬 | 直接報酬の期待値 | ||||
|---|---|---|---|---|---|---|---|---|
| S0 | S1 | S2 | S0 | S1 | S2 | |||
| S0(都市A) | 1 | 1/2 | 1/4 | 1/4 | 10 | 4 | 8 | 8 |
| 2 | 1/16 | 3/4 | 3/16 | 8 | 2 | 4 | 2.75 | |
| 3 | 1/4 | 1/8 | 5/8 | 4 | 6 | 4 | 4.25 | |
| S1(都市B) | 1 | 1/2 | 0 | 1/2 | 14 | 0 | 18 | 16 |
| 2 | 1/16 | 7/8 | 1/16 | 8 | 16 | 8 | 15 | |
| 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| S2(都市C) | 1 | 1/4 | 1/4 | 1/2 | 10 | 2 | 8 | 7 |
| 2 | 1/8 | 3/4 | 1/8 | 6 | 4 | 2 | 4 | |
| 3 | 3/4 | 1/16 | 3/16 | 4 | 0 | 8 | 4.5 | |
| 割引率(Discount rate) γ | 最適政策による行動 | 最適行動のQ値 | ||||
|---|---|---|---|---|---|---|
| S0(都市A) | S1(都市B) | S2(都市C) | S0(都市A) | S1(都市B) | S2(都市C) | |
| 0 | A0 | A0 | A0 | 8.00 | 16.00 | 7.00 |
| 0.05 | A0 | A0 | A0 | 8.51 | 16.40 | 7.50 |
| 0.10 | A0 | A0 | A0 | 9.08 | 16.86 | 8.05 |
| 0.15 | A0 | A1 | A0 | 9.71 | 17.46 | 8.67 |
| 0.20 | A0 | A1 | A0 | 10.44 | 18.48 | 9.38 |
| 0.25 | A0 | A1 | A0 | 11.27 | 19.63 | 10.21 |
| 0.30 | A0 | A1 | A0 | 12.24 | 20.93 | 11.16 |
| 0.35 | A0 | A1 | A0 | 13.38 | 22.43 | 12.28 |
| 0.40 | A0 | A1 | A0 | 14.72 | 24.17 | 13.61 |
| 0.45 | A0 | A1 | A0 | 16.33 | 26.21 | 15.21 |
| 0.50 | A0 | A1 | A0 | 18.30 | 28.64 | 17.16 |
| 0.55 | A0 | A1 | A1 | 20.79 | 31.61 | 19.83 |
| 0.60 | A0 | A1 | A1 | 24.03 | 35.33 | 23.46 |
| 0.65 | A0 | A1 | A1 | 28.28 | 40.10 | 28.13 |
| 0.70 | A0 | A1 | A1 | 34.06 | 46.44 | 34.37 |
| 0.75 | A0 | A1 | A1 | 42.32 | 55.29 | 43.11 |
| 0.80 | A1 | A1 | A1 | 55.08 | 68.56 | 56.27 |
| 0.85 | A1 | A1 | A1 | 77.25 | 90.81 | 78.43 |
| 0.90 | A1 | A1 | A1 | 121.65 | 135.31 | 122.84 |
| 0.95 | A1 | A1 | A1 | 255.02 | 268.76 | 256.20 |
参考文献:小笠原正巳,坂本武司 著,北川 敏男 編:情報科学講座(全62巻)A・5・1 マルコフ過程,共立出版 (1967).